I am currently most interested in understanding, from the perspective of internal model representations, how memory and reasoning differ in language models. My work focuses on three aspects of memory and reasoning: how they are acquired through learning, how they are preserved, and how they are used during model behavior. In addition, I am actively exploring the evolution of external memory, or more broadly, externalized capabilities that evolve through interaction over time.
2025
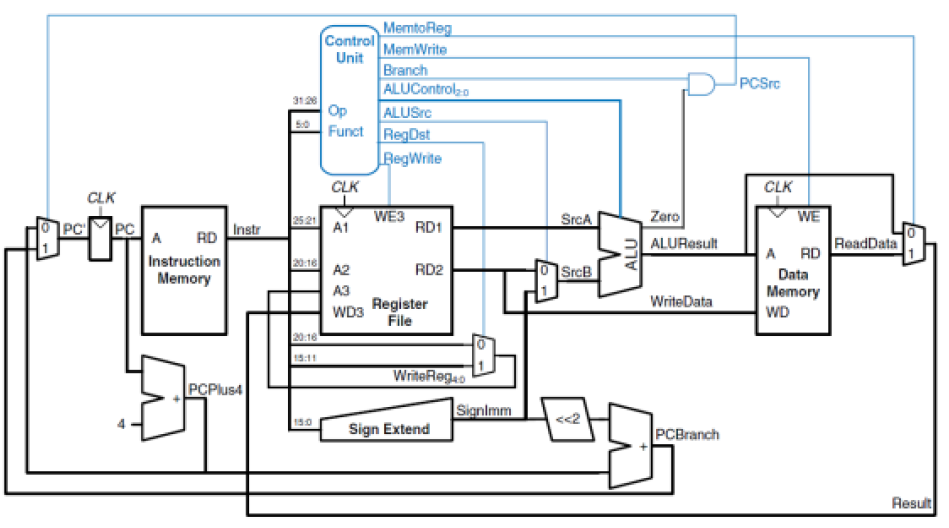
InSPECT: Invariant Spectral Features Preservation of Diffusion Models
Baohua Yan, Qingyuan Liu, Jennifer Kava, Xuan Di
Preprint
Proposed a Fourier-domain diffusion framework that explicitly models frequency consistency across classes and diffusion timesteps to mitigate information loss in standard DDPMs. Implemented frequency-aware denoising and adaptive spectral regularization to stabilize the generative process and improve cross-domain generalization.
# Controllable Diffusion
InSPECT: Invariant Spectral Features Preservation of Diffusion Models
Baohua Yan, Qingyuan Liu, Jennifer Kava, Xuan Di
Preprint
Proposed a Fourier-domain diffusion framework that explicitly models frequency consistency across classes and diffusion timesteps to mitigate information loss in standard DDPMs. Implemented frequency-aware denoising and adaptive spectral regularization to stabilize the generative process and improve cross-domain generalization.
# Controllable Diffusion
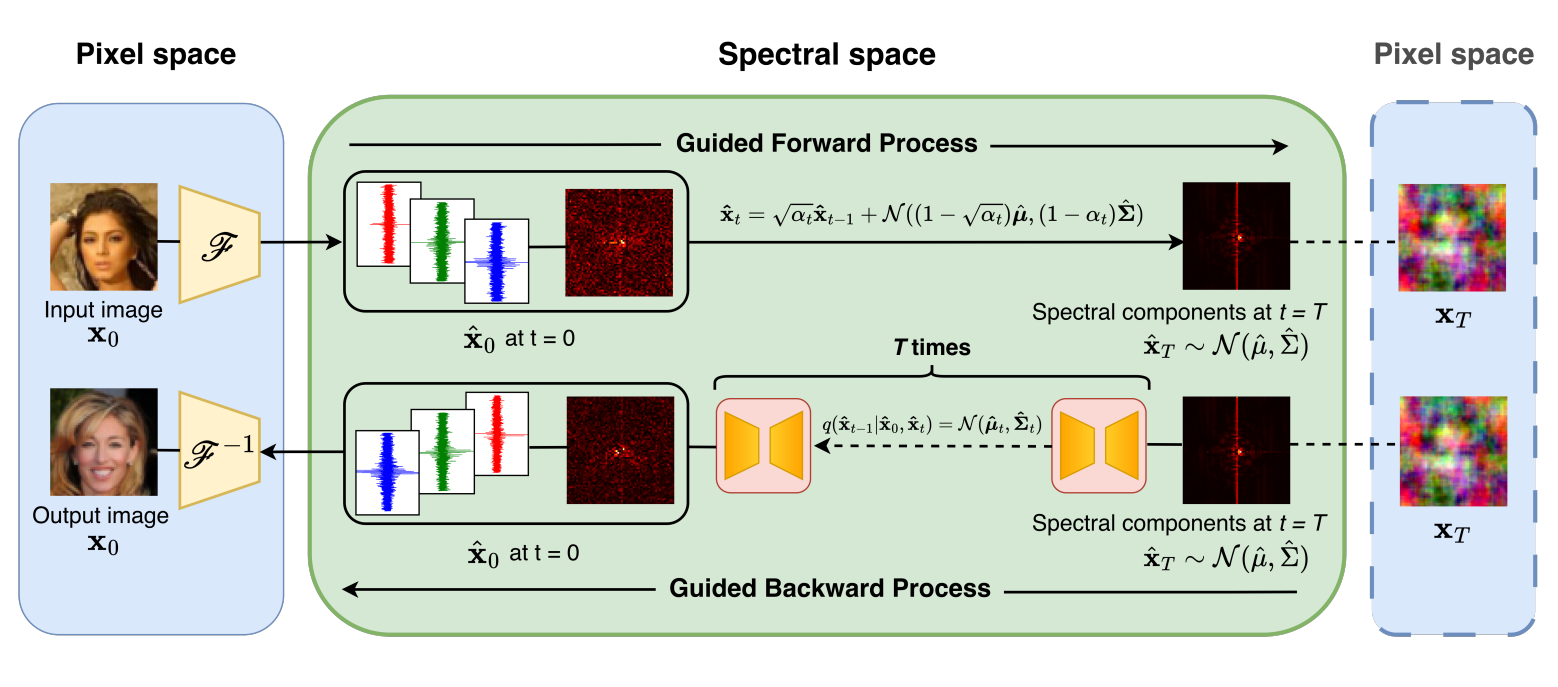
Energy-Regularized Sequential Model Editing on Hyperspheres
Qingyuan Liu*, Jiachen Gu*, Yunzhi Yao, Hong Wang, Nanyun Peng
In The Fourteenth International Conference on Learning Representations (ICLR). 2026.
Top-1.1% in Transfer/Meta/Lifelong Learning track
[TL;DR] [Paper] [NICE-Talk] [Code] [EasyEdit] [Project Page]
Developed SPHERE (Sparse Projection for Hyperspherical Energy-Regularized Editing), projecting new knowledge onto sparse hyperspherical subspaces to preserve uniformity and editing stability with rigorous proof, achieving +16.4% higher editing capability while best preserving general performance on LLaMA3-8B and Qwen2.5-7B.
# Model Editing # Knowledge Mechanisms # Lifelong Learning
Energy-Regularized Sequential Model Editing on Hyperspheres
Qingyuan Liu*, Jiachen Gu*, Yunzhi Yao, Hong Wang, Nanyun Peng
In The Fourteenth International Conference on Learning Representations (ICLR). 2026.
Top-1.1% in Transfer/Meta/Lifelong Learning track
[TL;DR] [Paper] [NICE-Talk] [Code] [EasyEdit] [Project Page]
Developed SPHERE (Sparse Projection for Hyperspherical Energy-Regularized Editing), projecting new knowledge onto sparse hyperspherical subspaces to preserve uniformity and editing stability with rigorous proof, achieving +16.4% higher editing capability while best preserving general performance on LLaMA3-8B and Qwen2.5-7B.
# Model Editing # Knowledge Mechanisms # Lifelong Learning
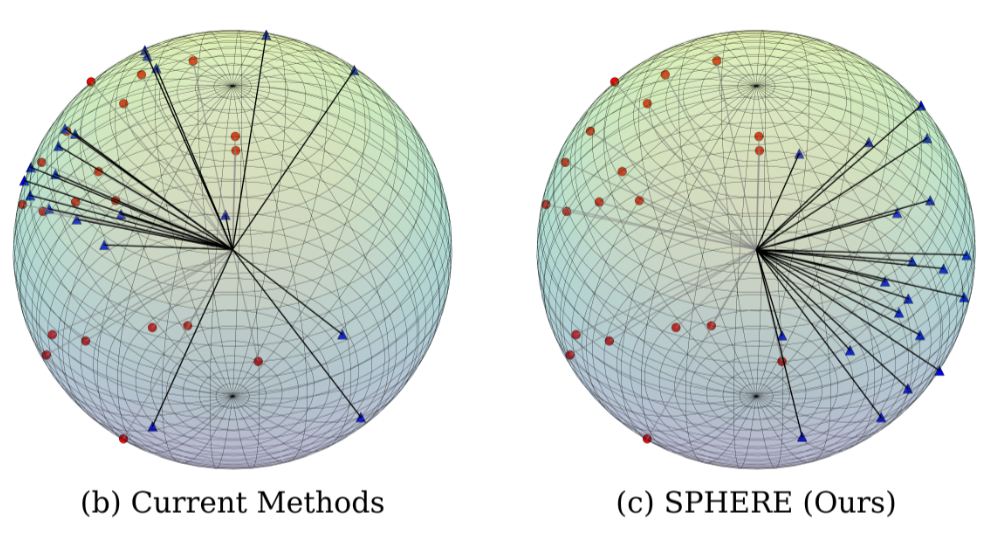
BALANCED LATENT SPACE OF DIFFUSION MODELS FOR COUNTERFACTUAL GENERATION
Baohua Yan, Qingyuan Liu, Zhaobin Mo, Kangrui Ruan, Xuan Di
The Thirteenth International Conference on Learning Representations, ICLR DeLTa workshop. 2025.
Proposed a controllable diffusion generation framework that balances latent space via guiding signals, enabling generation of counterfactual data while preserving factual consistency. Experiments on MNIST demonstrate its potential for counterfactual data generation.
# Controllable Diffusion
BALANCED LATENT SPACE OF DIFFUSION MODELS FOR COUNTERFACTUAL GENERATION
Baohua Yan, Qingyuan Liu, Zhaobin Mo, Kangrui Ruan, Xuan Di
The Thirteenth International Conference on Learning Representations, ICLR DeLTa workshop. 2025.
Proposed a controllable diffusion generation framework that balances latent space via guiding signals, enabling generation of counterfactual data while preserving factual consistency. Experiments on MNIST demonstrate its potential for counterfactual data generation.
# Controllable Diffusion
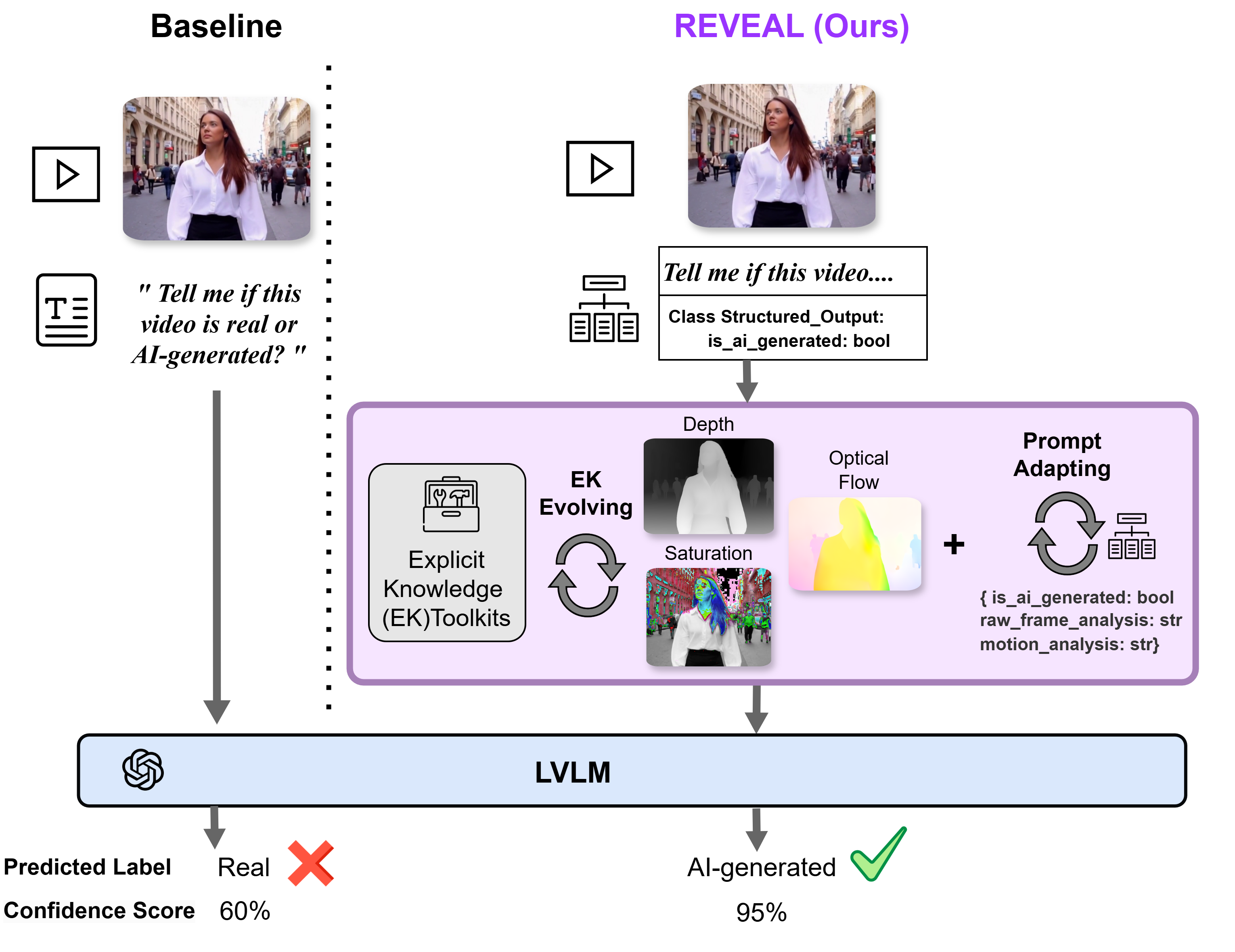
LAVID: An Agentic LVLM Framework for Diffusion-Generated Video Detection
Qingyuan Liu, Yun-Yun Tsai, Ruijian Zha, Pengyuan Shi, Victoria Li, Chengzhi Mao, Junfeng Yang
Preprint
Designed LAVID, an agentic LVLM-based framework integrating external tools (e.g. SAM) for AI-generated video detection, boosting F1 scores by 6.2%–30.2% across GPT-4o, Gemini-1.5-Pro, Qwen-VL, and LLaVA.
# AI-Synthetic # Agentic Framework
LAVID: An Agentic LVLM Framework for Diffusion-Generated Video Detection
Qingyuan Liu, Yun-Yun Tsai, Ruijian Zha, Pengyuan Shi, Victoria Li, Chengzhi Mao, Junfeng Yang
Preprint
Designed LAVID, an agentic LVLM-based framework integrating external tools (e.g. SAM) for AI-generated video detection, boosting F1 scores by 6.2%–30.2% across GPT-4o, Gemini-1.5-Pro, Qwen-VL, and LLaVA.
# AI-Synthetic # Agentic Framework
2024
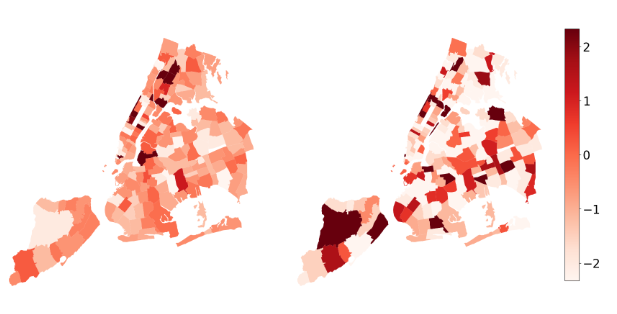
Causal Adjacency Learning for Spatiotemporal Prediction Over Graphs
Zhaobin Mo*, Qingyuan Liu*, Baohua Yan, Longxiang Zhang, Xuan Di
Proceeding of 27th IEEE International Conference on Intelligent Transportation Systems (ITSC). 2024
Designed the Causal Adjacency Learning (CAL) framework, enhancing prediction performance on the ODD dataset; applied a heuristic method combining correlation calculation and conditional independence testing; achieved +26.7% average RMSE improvement on SafeGraph dataset over baselines based on distance, correlation, and attention matrix.
# Graph Neural Networks
Causal Adjacency Learning for Spatiotemporal Prediction Over Graphs
Zhaobin Mo*, Qingyuan Liu*, Baohua Yan, Longxiang Zhang, Xuan Di
Proceeding of 27th IEEE International Conference on Intelligent Transportation Systems (ITSC). 2024
Designed the Causal Adjacency Learning (CAL) framework, enhancing prediction performance on the ODD dataset; applied a heuristic method combining correlation calculation and conditional independence testing; achieved +26.7% average RMSE improvement on SafeGraph dataset over baselines based on distance, correlation, and attention matrix.
# Graph Neural Networks

Turns Out I’m Not Real: Towards Robust Detection of AI-Generated Videos
Qingyuan Liu, Pengyuan Shi, Yun-Yun Tsai, Chengzhi Mao, Junfeng Yang
IEEE / CVF Computer Vision and Pattern Recognition Conference, GenAI Workshop. 2024
Columbia Engineering Research Highlight
Developed a Diffusion Reconstruction Error (DIRE) method for AI-generated video detection, leveraging video generation models with temporal cues to achieve up to 93.7% accuracy on Stable Video Diffusion, Sora, Pika, and Gen-2 datasets.
# AI-Synthetic
Turns Out I’m Not Real: Towards Robust Detection of AI-Generated Videos
Qingyuan Liu, Pengyuan Shi, Yun-Yun Tsai, Chengzhi Mao, Junfeng Yang
IEEE / CVF Computer Vision and Pattern Recognition Conference, GenAI Workshop. 2024
Columbia Engineering Research Highlight
Developed a Diffusion Reconstruction Error (DIRE) method for AI-generated video detection, leveraging video generation models with temporal cues to achieve up to 93.7% accuracy on Stable Video Diffusion, Sora, Pika, and Gen-2 datasets.
# AI-Synthetic
2022
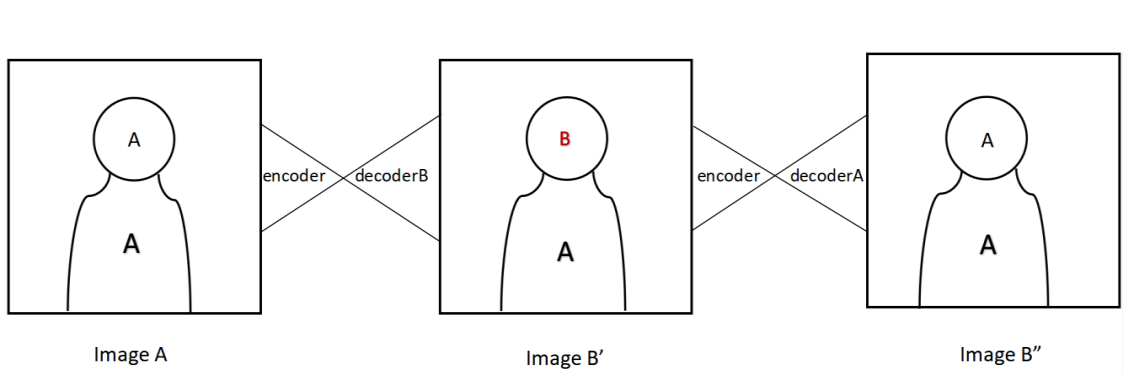
Accurate Face Swap using CycleGAN
Qingyuan Liu, Yuxuan Zhou, Shuai Bao
International Conference on Cloud Computing, Internet of Things, and Computer Applications (CICA). 2022.
Improve GAN-based face swapping under the CycleGAN framework, enabling training without paired images. The model is trained on over 1,000 images and can process video inputs to generate swapped-face videos within minutes. Experiments on Hillary and Trump videos demonstrate competitive quality and speed compared to other GAN-based methods.
# AI-Synthetic
Accurate Face Swap using CycleGAN
Qingyuan Liu, Yuxuan Zhou, Shuai Bao
International Conference on Cloud Computing, Internet of Things, and Computer Applications (CICA). 2022.
Improve GAN-based face swapping under the CycleGAN framework, enabling training without paired images. The model is trained on over 1,000 images and can process video inputs to generate swapped-face videos within minutes. Experiments on Hillary and Trump videos demonstrate competitive quality and speed compared to other GAN-based methods.
# AI-Synthetic